Captcha AI - Beispiel anhand von ReCaptcha
Detaillierte Analyse und Implementierung einer KI-basierten ReCaptcha-Lösung
Die Mission
Jeder kennt sie. Diese kleinen Checkboxen auf Websites: "Ich bin kein Roboter". Ein Klick, kurzes Warten, fertig. Manchmal jedenfalls.
Denn häufig erscheint nach dem Klick eine Bild-Challenge: "Wählen Sie alle Bilder mit Bussen aus", "Klicken Sie auf Ampeln", "Markieren Sie alle Fahrräder". Google's ReCaptcha v2, der Standard für Bot-Detection im Web.
Aber warum erscheint die Challenge manchmal gar nicht? Warum reicht manchmal ein einfacher Klick? Und die eigentlich spannende Frage: Können wir das automatisieren?
Spoiler: Ja. Mit Machine Learning, custom Labeling-Tools und etwas Kreativität. Natürlich alles rein theoretisch, zu Forschungszwecken.
Warum erscheint nicht immer eine Challenge?
ReCaptcha ist cleverer als es aussieht. Bevor überhaupt eine Bild-Challenge angezeigt wird, sammelt Google im Hintergrund massiv Daten über den Browser:
- Canvas Fingerprinting: Wie rendert der Browser Grafiken? Jede Hardware hat eine einzigartige "Signatur"
- WebGL Fingerprinting: GPU-spezifische Informationen, schwer zu fälschen
- User Behavior: Mausbewegungen, Klick-Pattern, Scroll-Verhalten, Menschen bewegen sich anders als Bots
- Cookies & History: War dieser Browser schon erfolgreich? Hat er eine "Vertrauens-Historie"?
- Browser-Eigenschaften: Plugins, Timezone, Language, Screen-Resolution, passt alles zusammen?
Basierend auf all diesen Faktoren vergibt ReCaptcha einen Vertrauens-Score. Ist der Score hoch genug, wird die Challenge direkt gelöst. Ist er zu niedrig, erscheint die Bild-Challenge. Und manchmal sogar mehrere hintereinander.
Die vier Challenge-Typen
Nicht alle ReCaptcha-Challenges sind gleich. Es gibt vier verschiedene Typen, die jeweils unterschiedliche Anforderungen und Schwierigkeitsgrade haben:
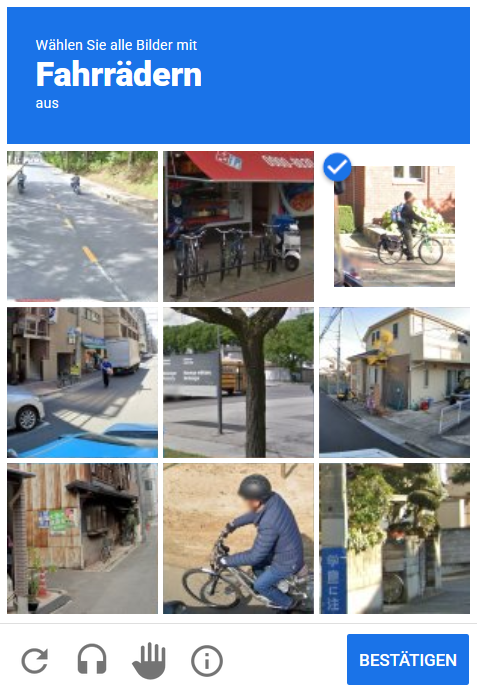
Ähnlich wie Dynamic, aber ohne nachladen. 9 fixe Bilder, alle richtigen müssen ausgewählt werden, dann Submit.
Für unsere Automatisierung bedeutet das: Wir brauchen unterschiedliche Strategien für unterschiedliche Challenge-Typen. Dazu später mehr.
Phase 1: Data Collection
Um ein Machine Learning Model zu trainieren, brauchen wir zuerst eins: Daten. Viele Daten. Tausende von Bildern, aus allen Challenge-Typen, mit allen möglichen Kategorien (Busse, Autos, Ampeln, Fahrräder, etc.).
Die Frage ist: Woher bekommen wir die? Wir könnten manuell Captchas lösen und Screenshots machen. Aber das wäre mühsam. Sehr mühsam. Also automatisieren wir das.
Browser-Automation mit Puppeteer
Wir nutzen Puppeteer, eine Node.js Library, die einen headless Chrome-Browser steuern kann. Der Plan: Demo-Seite laden, Captcha-Checkbox klicken, Challenge erscheint, Bild herunterladen. Dann refreshen und wiederholen. Wieder und wieder.
import puppeteer from "puppeteer";
import fs from "fs";
import request from "request";
const proxy = getRandomProxy();
const browser = await puppeteer.launch({
args: [`--proxy-server=${proxy.host}:${proxy.port}`],
headless: false,
});
const page = await browser.newPage();
await page.authenticate({
username: proxy.username,
password: proxy.password,
});
await page.goto("https://www.google.com/recaptcha/api2/demo");Wichtig: Proxy-Rotation. Google würde uns nach ein paar Dutzend Refreshes erkennen und blockieren. Also rotieren wir durch eine Liste von Proxies aus einer proxies.txt Datei. Jeder Browser-Neustart nutzt einen anderen Proxy.
Request-Interception & Challenge-Detection
Der Trick: Wir intercepten die API-Requests, die ReCaptcha im Hintergrund macht. Wenn der Browser eine neue Challenge lädt, wird ein Request an www.google.com/recaptcha/api2/reload gemacht. Die Response enthält alle Informationen über die Challenge.
page.on("response", async (res) => {
if (res.url().includes("www.google.com/recaptcha/api2/reload?")) {
let response = await res.text();
response = response.split(")]}'")[1]; // Google's Anti-XSSI Prefix entfernen
let data = JSON.parse(response);
let type = data[5]; // "dynamic", "imageselect", "tileselect", "multicaptcha"
let id = data[9]; // Unique Challenge-ID
let category;
switch (type) {
case "dynamic":
case "tileselect":
case "imageselect":
category = data[4][1][0]; // z.B. "/m/01bjv" (Bus)
break;
case "multicaptcha":
category = data[4][5][0][0][0]; // Tieferer Pfad für Multicaptcha
break;
}
// Bild-URL konstruieren und herunterladen
const url = `https://www.google.com/recaptcha/api2/payload?p=${id}&k=6Le-wvkSAAAAAPBMRTvw0Q4Muexq9bi0DJwx_mJ-`;
download(url, `./images/${type}/${category}`, `${id}.png`);
}
});Die data-Struktur ist spannend. Google liefert uns nicht nur das Bild, sondern auch den Challenge-Typ und die Kategorie. Perfekt für unsere automatische Sortierung.
Download & Kategorisierung
Jedes heruntergeladene Bild wird automatisch in Ordner sortiert: ./images/dynamic/bus/, ./images/multicaptcha/car/, etc. Das macht es später einfacher, die Daten zu organisieren.
Der Collector läuft im Loop: Captcha laden → Challenge analysieren → Bild speichern → Reload-Button klicken → Neue Challenge → Repeat. Ein Interval sorgt dafür, dass alle 1-2 Sekunden ein Reload getriggert wird.
Nach ein paar Stunden (und vielen Proxy-Wechseln) haben wir genügend Daten: Tausende von Bildern, sauber kategorisiert nach Typ und Objekt. Perfekt als Basis für unser Training.
dynamic und imageselect machen zusammen etwa 70% aller Challenges aus. multicaptcha ist mit ~10% relativ selten.Phase 2: Dataset Preparation
Wir haben jetzt Tausende von Bildern. Aber es gibt ein Problem: Die dynamic, imageselect und tileselect Bilder sind 3x3 Grids. Wir brauchen aber einzelne Bilder für unser Training, jedes Tile separat.
Die Lösung: Wir splitten jedes 3x3 Grid in 9 einzelne Bilder. Aus einem Captcha werden 9 Trainingsbilder.
Image Splitting mit Sharp
Wir nutzen sharp, eine performante Image-Processing Library für Node.js. Die Logik ist simpel: Grid-Größe berechnen, dann jedes Tile einzeln extrahieren.
import sharp from "sharp";
const inputImagePath = "./images/dynamic/bus/challenge_123.png";
sharp(inputImagePath)
.metadata()
.then(({ width, height }) => {
const squareWidth = Math.floor(width / 3);
const squareHeight = Math.floor(height / 3);
for (let row = 0; row < 3; row++) {
for (let col = 0; col < 3; col++) {
const left = col * squareWidth;
const top = row * squareHeight;
const outputPath = `./split/tile_${row}_${col}.png`;
sharp(inputImagePath)
.extract({ left, top, width: squareWidth, height: squareHeight })
.png({ quality: 100 })
.toFile(outputPath);
}
}
});Jedes Original-Bild wird in 9 Tiles zerlegt und mit eindeutigen Namen gespeichert. Aus challenge_123.png werden tile_0_0.png bis tile_2_2.png.
Labeling: Das mühsame aber notwendige
Jetzt haben wir Tausende einzelne Tiles. Aber unser Model braucht Labels: Welches Tile enthält einen Bus? Welches nicht? Das ist der Teil, den wir nicht vollständig automatisieren können, zumindest nicht am Anfang.
Also bauen wir ein Custom Labeling Tool. Eine simple HTML/JavaScript Applikation, die Bilder lädt und uns erlaubt, sie schnell zu kategorisieren.
Das Interface ist bewusst minimalistisch: Ein großes Bild in der Mitte, Keyboard-Shortcuts für maximale Geschwindigkeit. Mit etwas Übung lassen sich ~500 Bilder pro Stunde labeln.
// Keyboard-Shortcuts für schnelles Labeling
document.onkeyup = function (e) {
if (e.key === "ArrowUp" || e.key === "w") {
labelImage(true); // Enthält Objekt
setTimeout(nextImage, 100);
}
if (e.key === "ArrowDown" || e.key === "s") {
labelImage(false); // Enthält kein Objekt
setTimeout(nextImage, 100);
}
if (e.key === "ArrowRight" || e.key === "d") {
nextImage(); // Nächstes Bild (ohne Label)
}
if (e.key === "ArrowLeft" || e.key === "a") {
previousImage(); // Vorheriges Bild
}
};
Sobald alle Bilder gelabelt sind, werden sie in zwei Ordner exportiert: yes/ und no/. Perfekt strukturiert für unser Training.
Klassifizierung vs. Lokalisierung
Bevor wir ins Training einsteigen, müssen wir eine fundamentale Frage klären: Welchen Ansatz nutzen wir?
Wir haben vier Challenge-Typen, aber eigentlich zwei verschiedene Problemstellungen:
- 3x3 Challenges (dynamic, imageselect, tileselect): 9 separate Bilder → Ja/Nein pro Bild
- 4x4 Multicaptcha: Ein großes Bild → Objekt finden und alle betroffenen Tiles markieren
Für diese zwei Problemstellungen brauchen wir unterschiedliche Machine Learning Ansätze.
Ansatz 1: Binary Classification
Für die 3x3 Challenges ist die Lösung einfach: Binäre Klassifikation. Wir trainieren ein Model, das für jedes einzelne Tile die Frage beantwortet: "Enthält dieses Bild einen Bus?" → Ja oder Nein.
Vorteile
Warum Binary Classification für 3x3 Grids perfekt ist
- Einfaches Training (nur 2 Klassen: yes/no)
- Schnelle Inference (wenige Millisekunden pro Bild)
- Wenig Rechenleistung nötig
- Funktioniert hervorragend für klare Objekte
Nachteile
Einschränkungen des Ansatzes
- Funktioniert nicht für Multicaptcha
- Kann nicht mit Teil-Objekten umgehen (nur Ausschnitt sichtbar)
- Keine räumliche Information über Objekt-Position
Der Workflow: Captcha-Bild laden → In 9 Tiles splitten → Jedes Tile durch das Model laufen lassen → Die "Yes"-Tiles sind unsere Antwort.
Ansatz 2: Object Detection (Lokalisierung)
Für Multicaptcha reicht Binary Classification nicht. Warum? Ein einzelnes Tile kann nur einen Teil des Objekts zeigen, z.B. nur die Räder eines Busses. Das Model würde sagen: "Ich sehe keine typischen Bus-Merkmale" → Nein. Aber das Tile sollte trotzdem ausgewählt werden, weil es Teil des Busses ist.
Die Lösung: Object Detection. Anstatt nur zu fragen "Ist da ein Bus?", fragen wir "Wo genau ist der Bus?". Das Model zeichnet eine Bounding Box um das Objekt. Dann schauen wir, welche Tiles die Box überschneidet.
Vorteile
Warum Object Detection für Multicaptcha essentiell ist
- Funktioniert perfekt für Multicaptcha (findet Objekt-Position)
- Erkennt auch Teil-Objekte korrekt
- Kann mehrere Objekte im selben Bild lokalisieren
- Liefert präzise räumliche Information
Nachteile
Einschränkungen und Kosten
- Komplexeres Training (braucht Bounding-Box-Labels)
- Deutlich rechenintensiver (mehrere 100ms pro Bild)
- Braucht mehr GPU-Power
- Overkill für simple 3x3 Challenges
Der Workflow: Captcha-Bild laden → Object Detection Model anwenden → Bounding Box erhalten → 4x4 Grid darüber legen → Alle Tiles die die Box überschneiden sind unsere Antwort.
Fazit: Wir nutzen beide Ansätze. Binary Classification für die 3x3 Challenges (schnell und effizient), Object Detection für Multicaptcha (präzise und robust). Best of both worlds.
Phase 3: Binary Classification Training
Jetzt wird es spannend. Wir haben gelabelte Daten, wir wissen welchen Ansatz wir nutzen, Zeit für das eigentliche Training.
Aber: Wir starten nicht bei Null. Ein neuronales Netzwerk komplett von Grund auf zu trainieren würde Wochen dauern und Millionen von Bildern brauchen. Stattdessen nutzen wir Transfer Learning.
EfficientNet: Pre-trained Powerhouse
Wir basieren unser Model auf EfficientNetB0, einem hochoptimierten Convolutional Neural Network, das bereits auf ImageNet trainiert wurde. ImageNet enthält Millionen von Bildern mit Tausenden von Kategorien, inklusive... Busse, Autos, Fahrräder. Perfekt.
Die Ironie: Google's ReCaptcha nutzt Objekte, die in öffentlichen ML-Datasets reichlich vorhanden sind. Wir nutzen quasi Google's eigene Trainingsdaten gegen sie.
from keras._tf_keras.keras.applications import EfficientNetB0
from keras import layers, models
# Basis-Model laden (Pre-trained auf ImageNet)
base_model = EfficientNetB0(
weights='imagenet',
include_top=False, # Ohne Classification-Layer
input_shape=(100, 100, 3)
)
base_model.trainable = False # Erst einmal einfrieren
# Eigene Classification-Layer hinzufügen
model = models.Sequential([
base_model,
layers.GlobalAveragePooling2D(),
layers.Dense(512, activation='relu'),
layers.Dropout(0.5),
layers.Dense(1, activation='sigmoid') # Binary: 0 oder 1
])
model.compile(
optimizer='Adam',
loss='binary_crossentropy',
metrics=['accuracy']
)Der Trick: Wir nutzen EfficientNet als Feature Extractor. Das Netzwerk hat bereits gelernt, wichtige Merkmale in Bildern zu erkennen (Kanten, Formen, Texturen). Wir trainieren nur die letzten Layer, um diese Features auf unsere spezifische Aufgabe zu mappen.
Training Setup & Data Augmentation
Unser Datensatz ist nicht riesig, ein paar Tausend Bilder. Um Overfitting zu vermeiden, nutzen wir Data Augmentation: Rotation, Zoom, Shift, Horizontal Flip. Aus einem Trainingsbild werden dutzende leicht variierte Versionen.
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=10, # ±10° Rotation
width_shift_range=0.1, # 10% horizontale Verschiebung
height_shift_range=0.1, # 10% vertikale Verschiebung
shear_range=0.1,
zoom_range=0.1,
horizontal_flip=True,
fill_mode='nearest'
)
# Class Weights für unbalancierte Daten
class_weight = {0: 1., 1: 2.03} # "Yes"-Klasse gewichten
# Training mit Early Stopping
early_stopping = tf.keras.callbacks.EarlyStopping(
monitor='val_loss',
patience=10,
restore_best_weights=True
)
history = model.fit(
train_generator,
validation_data=validation_generator,
epochs=50,
callbacks=[early_stopping],
class_weight=class_weight
)Nach dem initialen Training mit eingefrorenen Basis-Layern, frieren wir nur die letzten 30 Layer auf und trainieren nochmal mit reduzierter Learning-Rate. Fine-Tuning für maximale Accuracy.
Der Validator-Trick: Pre-Labeling
Nach dem ersten Training haben wir bereits eine Accuracy von [INITIAL_ACCURACY]. Nicht perfekt, aber gut genug für einen cleveren Trick:
Wir nutzen das trainierte Model, um neue Bilder automatisch vorzulabeln. Dann bauen wir ein zweites Tool, den Validator, der nur noch eine Frage stellt: "Ist das Label korrekt?"
# Pre-Labeling mit trainiertem Model
model = tf.keras.models.load_model('bus_classifier_model.h5')
for img_name in os.listdir('./unlabeled'):
img = image.load_img(img_path, target_size=(100, 100))
img_array = image.img_to_array(img)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
prediction = model.predict(img_array)
result = "yes" if prediction[0] > 0.5 else "no"
# In entsprechenden Ordner verschieben
os.rename(img_path, f"./classify/{result}/{i}.png")Anstatt jedes Bild manuell zu labeln, korrigieren wir nur noch die Fehler des Models. Das ist um Größenordnungen schneller. Aus 500 Bildern/Stunde werden 2000+ Bilder/Stunde.
Mit dem erweiterten Datensatz trainieren wir erneut. Die Accuracy steigt auf [FINAL_ACCURACY]. Das Model ist jetzt robust genug für den Einsatz.
Phase 4: YOLO für Multicaptcha
Multicaptcha ist die Herausforderung. Ein 4x4 Grid, ein großes Bild, ein Objekt das sich über mehrere Tiles erstreckt. Binary Classification würde hier scheitern, wir brauchen Object Detection.
Das Problem mit Teil-Objekten
Stell dir vor: Ein Bus nimmt 4 Tiles ein. Tile 1 zeigt die Front, Tile 2 die Seite, Tile 3 nur ein Fenster, Tile 4 nur einen Reifen. Unser Binary Classifier würde bei Tile 1 und 2 "Yes" sagen, die haben klare Bus-Merkmale. Aber Tile 3 und 4? Nur ein Fenster, nur ein Reifen? "No", zu wenig Kontext.
Aber die Challenge verlangt alle Tiles, die das Objekt enthalten. Auch die mit nur Teilstücken. Die Lösung: Lokalisierung statt Klassifikation.
YOLO: You Only Look Once
YOLO ist ein State-of-the-Art Object Detection Model. Es analysiert das gesamte Bild in einem Durchlauf und liefert Bounding Boxes um alle erkannten Objekte. Perfekt für unseren Use-Case.
Wir nutzen zwei Ansätze parallel:
- YOLO auf COCO trainiert: COCO ist ein riesiger Dataset mit 80 Kategorien, inklusive vielen ReCaptcha-Objekten (cars, buses, traffic lights, bicycles, motorcycles, etc.)
- Custom YOLO auf ReCaptcha-Daten trainiert: Für Objekte die COCO nicht abdeckt (stairs, crosswalks, chimneys, etc.)
from ultralytics import YOLO
# Pre-trained YOLO auf COCO
coco = YOLO('./models/coco.pt')
# Custom trainierte Models
recaptcha = YOLO('./models/recaptcha.pt')
# Kategorien die von welchem Model unterstützt werden
classes_recaptcha = {
'bicycles': 0, 'bridges': 1, 'buses': 2, 'chimneys': 3,
'crosswalks': 4, 'fire hydrants': 5, 'motorcycles': 6,
'parking meters': 7, 'stairs': 8, 'taxis': 9,
'tractors': 10, 'traffic lights': 11, 'vehicles': 12
}
classes_coco = {
'people': 0, 'bicycles': 1, 'cars': 2, 'motorcycles': 3,
'buses': 5, 'traffic lights': 9, 'fire hydrants': 10,
# ... 80 Kategorien total
}Google Colab: GPU-Power on Demand
YOLO-Training ist rechenintensiv. Lokal würde das Training ~30 Stunden dauern. Die Lösung: Google Colab. Cloud-basierte Jupyter Notebooks mit kostenlosen (oder günstigen) GPU-Instanzen.
Mit einer T4 GPU schrumpft die Trainingszeit auf ~30 Minuten. Upload der Daten, Training starten, Kaffee holen, fertiges Model downloaden. Perfekt.
Grid-Intersection: Von Boxes zu Tiles
YOLO liefert uns Bounding Boxes: [x_min, y_min, x_max, y_max]. Aber wir brauchen Tile-Indices: [0, 1, 4, 5]. Die Logik: 4x4 Grid über das Bild legen, dann schauen welche Tiles die Box überschneidet.
def locate(image, category):
results = model(source=image)
boxes = results[0].boxes
class_ids = boxes.cls
# Filter für gewünschte Kategorie
class_id = classes[category]
target_boxes = boxes[class_ids == class_id]
# Grid-Parameter
img_height, img_width, _ = image.shape
square_size_h = img_height // 4
square_size_w = img_width // 4
squares_with_boxes = []
coverage_threshold = 0.1 # 10% Überschneidung reicht
# Für jedes Tile prüfen ob es Box überschneidet
for i in range(4):
for j in range(4):
square = [j * square_size_w, i * square_size_h,
(j+1) * square_size_w, (i+1) * square_size_h]
for box in target_boxes:
intersection_area = calculate_intersection_area(box, square)
square_area = square_size_w * square_size_h
if intersection_area / square_area > coverage_threshold:
squares_with_boxes.append(i * 4 + j)
break
return squares_with_boxesDer coverage_threshold von 0.1 bedeutet: Wenn 10% oder mehr des Tiles von der Box überdeckt werden, zählt es als "getroffen". Das fängt auch Tiles mit nur kleinen Teil-Objekten ab.
Phase 5: API Implementation
Wir haben zwei Models: Binary Classification für 3x3, Object Detection für 4x4. Jetzt bringen wir alles zusammen in einer unified API.
Die Architektur
Input: Ein Captcha-Bild + Challenge-Typ + Kategorie (z.B. "bus").
Output: Liste von Tile-Indices, die geklickt werden sollen.
# classify.py - Binary Classification
import tensorflow as tf
bus = tf.keras.models.load_model('./models/bus.h5')
car = tf.keras.models.load_model('./models/car.h5')
traffic_light = tf.keras.models.load_model('./models/traffic_light.h5')
categories = {
"bus": bus,
"car": car,
"traffic_light": traffic_light,
# ... weitere Kategorien
}
def classify(image, category):
model = categories[category]
# Image preprocessing
img_array = image.img_to_array(image)
img_array = np.expand_dims(img_array, axis=0)
img_array /= 255.0
prediction = model.predict(img_array)
return (prediction[0] > 0.5).item() # True/False# locate.py - Object Detection
from ultralytics import YOLO
coco = YOLO('./models/coco.pt')
recaptcha = YOLO('./models/recaptcha.pt')
def locate(image, category):
# Model-Selection basierend auf Kategorie
if category in classes_recaptcha:
model = recaptcha
elif category in classes_coco:
model = coco
else:
raise ValueError("Invalid category")
results = model(source=image)
# ... Grid-Intersection-Logic (siehe oben)
return squares_with_boxes # [0, 1, 4, 5]Workflow: Von Challenge zu Lösung
Die komplette Pipeline:
[0, 2, 3, 7]Ein erfolgreicher Test mit einem Bus-Captcha:
# Test: Dynamic Challenge mit Bus
image = load_image("challenge_bus_dynamic.png")
tiles = split_image_3x3(image) # 9 Tiles
results = []
for idx, tile in enumerate(tiles):
if classify(tile, "bus"): # Model sagt "Yes"
results.append(idx)
print(f"Tiles to click: {results}")
# Output: Tiles to click: [0, 1, 3, 4, 6]
# ✅ Challenge erfolgreich gelöst!Technical Stack: Die Sprachen-Wahl
Aufmerksamen Lesern ist es aufgefallen: Wir nutzen zwei verschiedene Programmiersprachen. JavaScript für Data Collection und Labeling, Python für Machine Learning. Warum?
JavaScript / Node.js
Browser-Automation und Data Processing
Python
Machine Learning und Model Training
Right tool for the job. JavaScript glänzt bei Browser-Automation und DOM-basierten UIs. Python ist unschlagbar im ML-Bereich. Die Interoperabilität? Einfach über das File-System, Bilder speichern, Models laden, Ergebnisse zurückschreiben.
Root Cause Analysis
Wir haben ReCaptcha v2 erfolgreich umgangen. Aber warum funktioniert das überhaupt? Was sind die fundamentalen Schwachstellen?
1. Nur Lösungs-Validierung, kein Pattern-Detection
ReCaptcha v2 prüft nur eines: "Wurden die richtigen Tiles ausgewählt?" Es prüft nicht:
- Wie schnell wurden die Tiles ausgewählt?
- In welcher Reihenfolge wurden sie geklickt?
- Wie "menschlich" war das Klick-Pattern?
- Gab es Mausbewegungen zwischen den Klicks?
Das macht die Challenge rein zu einem Computer-Vision-Problem. Und Computer Vision ist 2024/2025 ein gelöstes Problem für Standard-Objekte.
2. ImageNet hilft den Angreifern
Die Ironie des Ganzen: ReCaptcha nutzt Alltagsobjekte (Busse, Autos, Ampeln, Fahrräder), für die es Millionen von Trainingsdaten gibt. ImageNet, COCO, OpenImages, alle diese Datasets enthalten genau die Objekte, die ReCaptcha fragt.
Google nutzt quasi öffentliche ML-Datasets gegen sich selbst. Transfer Learning macht es trivial, diese Pre-trained Models auf ReCaptcha zu adaptieren.
3. Browser-Fingerprinting umgehbar
Ja, ReCaptcha macht Browser-Fingerprinting. Aber Puppeteer mit den richtigen Stealth-Plugins kann das umgehen. Canvas-Fingerprinting? Randomisiert. WebGL? Gefälscht. User-Behavior? Simuliert mit zufälligen Delays und Mausbewegungen.
Die einzige echte Defense war das Rate-Limiting. Aber auch das umgehen wir mit Proxy-Rotation.
4. Die Lösung: ReCaptcha v3 & Behavioral Analysis
Google hat diese Probleme erkannt. ReCaptcha v3 verzichtet komplett auf Challenges und gibt stattdessen nur einen Score (0.0 bis 1.0). Dieser Score basiert auf:
- Langzeit-Verhalten des Users auf der gesamten Website
- Interaktions-Pattern (Scroll-Verhalten, Klick-Timing, etc.)
- Device-Historie und Trust-Score
- Kontext-Signale (Tageszeit, Geolocation, etc.)
Das ist deutlich schwerer zu umgehen. Aber auch nicht unmöglich, nur komplexer und zeitaufwändiger.
hCaptcha: Der nächste Level
ReCaptcha v2 ist nicht die einzige Captcha-Lösung. Ein Konkurrent hat in den letzten Jahren massiv aufgeholt: hCaptcha. Und sie haben aus Google's Fehlern gelernt.
KI-generierte Bilder & Daily Rotation
hCaptcha's neue Strategie ist clever: Anstatt echte Fotos zu nutzen (die in ML-Datasets vorkommen könnten), generieren sie ihre Bilder mit KI. Stable Diffusion, DALL-E und ähnliche Models erstellen täglich neue Challenge-Bilder.
Das bedeutet:
- Keine Pre-trained Models helfen: Die Bilder existieren nicht in ImageNet oder COCO
- Täglich wechselnde Stile: Was gestern funktionierte, scheitert heute
- Watermarks & Visual Noise: Subtile Störungen, die ML-Models verwirren aber Menschen nicht beeinträchtigen
- Ungewöhnliche Perspektiven: Objekte aus Winkeln, die in normalen Trainings-Daten selten sind
Das ist eine echte Herausforderung. Standard-Ansätze wie unserer funktionieren hier nicht mehr. Man kann nicht einfach ein Model trainieren, wenn sich die Daten täglich ändern.
Meine Lösung (Spoiler: Classified)
Ich habe auch hCaptcha geknackt. Ein System, das automatisch auf neue Challenge-Typen adaptiert, ohne Retraining, ohne manuelle Anpassung. Es funktioniert für alle täglichen Variationen, alle generierten Stile, alle Objekt-Kategorien.
Zum Zeitpunkt der Entwicklung war ich einer der ersten weltweit, der das geschafft hat. Ein echter Durchbruch im Bereich adversarial ML.
Aber: Die Details bleiben unter Verschluss. Das Projekt ist nicht öffentlich und wird es auch nicht werden. Warum? Responsible Disclosure bedeutet auch zu wissen, wann man etwas nicht veröffentlicht. Ein vollautomatisches hCaptcha-Bypass-System wäre zu mächtig in den falschen Händen.
Was ich sagen kann: Die Zukunft von Captchas ist ein Wettrüsten. AI vs. AI. Generative Models für Challenges, Adaptive ML für Bypasses. Und mittendrin: Die Frage, wie wir Bots von Menschen unterscheiden, wenn beide AI-gestützt sind.
Key Takeaways
Was können wir aus diesem Projekt lernen?
- Defense in Depth ist entscheidend: ReCaptcha v2 als einzige Security-Maßnahme ist nicht genug. Kombiniert Captchas mit Rate-Limiting, Behavioral Analysis, Session-Validierung und Multi-Factor-Authentication.
- AI vs. AI, Das neue Normal: Wenn beide Seiten Machine Learning nutzen, wird es zum Wettrüsten. Generative Models für Challenges, Adaptive ML für Bypasses. Die Zukunft ist dynamisch, nicht statisch.
- Transfer Learning ist mächtig: Man muss nicht bei Null anfangen. EfficientNet, YOLO, pre-trained auf riesigen Datasets , diese Models liefern 90% der Performance mit 10% des Aufwands. Stehen auf den Schultern von Giganten.
- Visual Challenges allein reichen nicht: Solange die Validierung nur "richtige Antwort ja/nein" ist, kann man sie automatisieren. Behavioral Analysis, wie wurde gelöst, nicht nur was, ist die Zukunft.
- Custom Tools beschleunigen alles: Das Labeling-Tool und der Validator haben Wochen an Arbeit gespart. Manchmal ist es schneller, das richtige Werkzeug zu bauen, als mit unpassenden Tools zu kämpfen.
- Mit großer Macht kommt große Verantwortung: Nur weil man etwas kann, heißt nicht, dass man es sollte. Manche Projekte bleiben besser im Forschungs-Kontext. Responsible Disclosure bedeutet auch Zurückhaltung.
Ethical Considerations
Bei dieser Art von Research ist es wichtig, ethische Grenzen zu beachten:
- Responsible Disclosure: Die Schwachstellen von ReCaptcha v2 sind bereits bekannt und das System wurde weitgehend durch v3 ersetzt. Die hCaptcha-Lösung bleibt bewusst im Detail unveröffentlicht, manche Dinge bleiben besser im Forschungs-Kontext.
- Keine Massenexploitation: Solche Techniken sollten nicht für eigene Vorteile ausgenutzt werden. Nur weil man etwas kann, heißt nicht, dass man es sollte.
- Educational Purpose: Dieses Write-Up dient der Bildung und zeigt Konzepte, nicht fertige Tools. Die Lücke zwischen "Konzept verstehen" und "produktionsreifes System bauen" ist groß, absichtlich.
Fazit
ReCaptcha v2 mit Machine Learning zu umgehen ist 2024/2025 technisch simpel. Binary Classification für 3x3 Challenges, Object Detection für Multicaptcha, Transfer Learning von ImageNet und COCO, das Rezept ist bekannt.
Das eigentliche Learning: Captchas sind nicht tot, aber sie entwickeln sich. Von statischen Bild-Challenges zu KI-generierten, täglich wechselnden Variationen. Von reiner Lösungs-Validierung zu Behavioral Analysis. Von "Ich bin kein Roboter" zu "Wie menschlich verhält sich dieser User?"
Die Zukunft ist ein Wettrüsten. AI vs. AI. Und in der Mitte: Wir Menschen, die versuchen herauszufinden, wer Mensch und wer Maschine ist, während beide immer ähnlicher werden.
Das Katz-und-Maus-Spiel zwischen Bot-Detection und Bot-Creation geht weiter. Und das ist gut so. Denn nur im Wettrüsten entstehen echte Innovationen.